

Insights on AI Hardware Strategy, Edge AI Architecture, and Semiconductor Innovation
FEATURED INSIGHT:
Lighthouse AI Technologies Files Provisional Patent for Adaptive Edge AI Architecture
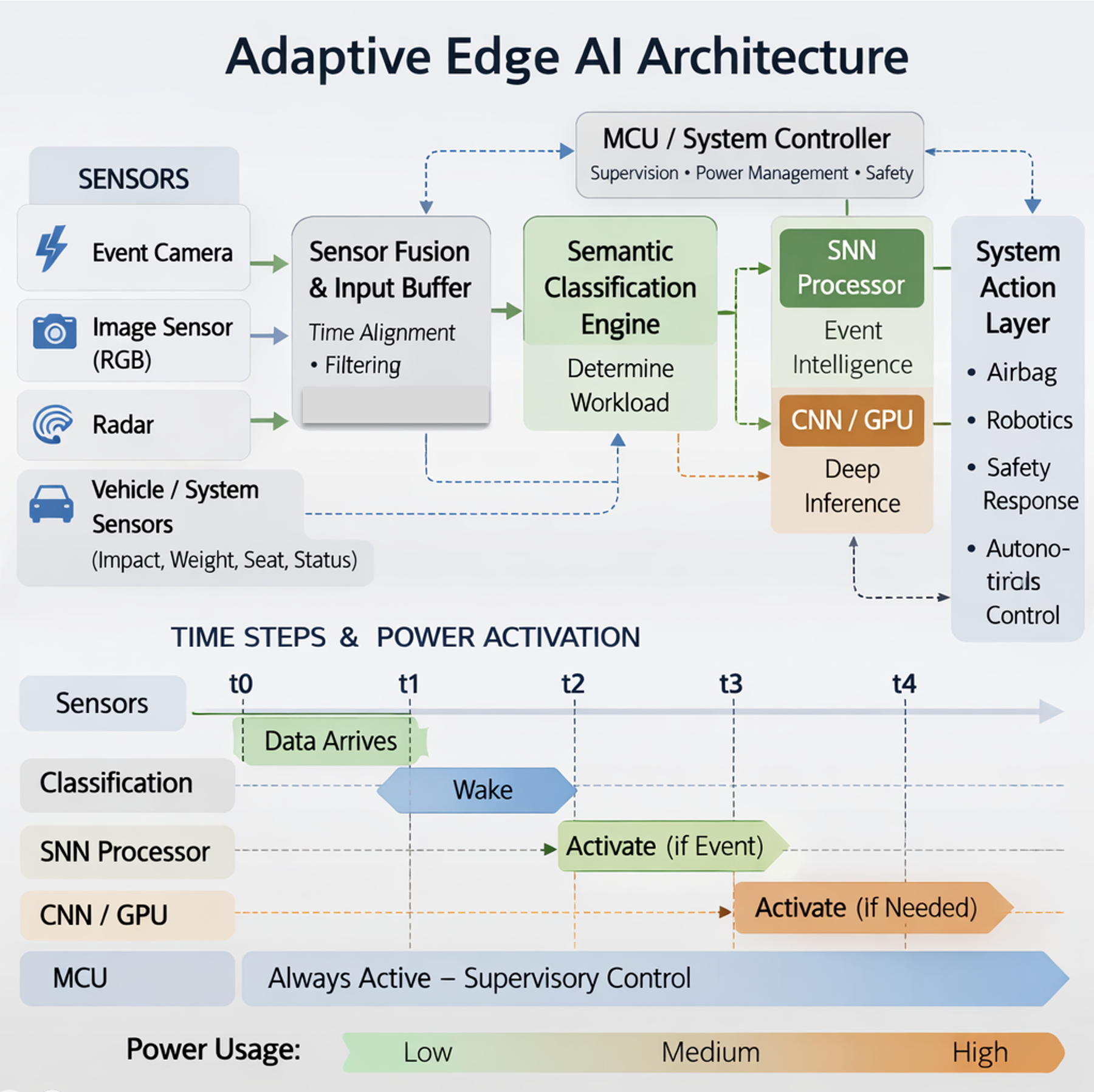
Conceptual architecture illustrating adaptive workload routing across heterogeneous edge compute resources.
Lighthouse AI Technologies recently filed a U.S. provisional patent application covering an adaptive edge computing architecture designed to improve how artificial intelligence systems operate in power-constrained environments.
The concept explores how semantic interpretation of sensor inputs could dynamically route workloads across heterogeneous compute resources at the edge. By selectively activating different inference engines based on the nature of incoming data, the architecture aims to balance power consumption, latency, and system responsiveness.
As AI continues moving from centralized cloud infrastructure to distributed edge environments, system-level orchestration of compute resources will become increasingly important. Edge AI platforms must manage diverse workloads across sensors, processors, and accelerators while operating within strict energy and performance constraints.
This work reflects Lighthouse AI Technologies’ ongoing focus on AI hardware strategy, edge inference architectures, and semiconductor system innovation.
More insights on AI hardware and edge computing architectures will be shared here as the field continues to evolve.

Latest insights…
From Metrics to Meaning: A System-Level Approach to Preventative Maintenance
Years ago, I led the development of a system to detect mechanical issues in industrial motors — not by measuring vibration directly, but by analyzing subtle changes in motor current.
The idea was simple, but non-obvious: use FFT-based analysis to identify high-frequency signatures that indicate imbalance, wear, or early failure.
I developed the concept and worked with a team to build and prove it.
The result wasn’t just better monitoring — it enabled something far more valuable:
planned shutdowns instead of unexpected failures.
Recently, I found myself revisiting that same thinking — in a very different context.
After filing a provisional patent, I became more focused on ensuring my own data, work, and client materials were protected, controlled, and resilient to failure.
That led me to my NAS.
What started as basic monitoring quickly turned into something more intentional.
From Monitoring to Understanding
At first, it was the usual metrics:
CPU usage, memory, disk activity.
But that quickly felt incomplete — just isolated data points without context.
So I expanded the view:
Power consumption via UPS
Thermal behavior across CPU and board-level sensors
Workload activity over time
Drive health monitoring (SMART)
Trigger-based alerts for power, thermal, and system events
The goal wasn’t more data. It was context.
The Reality of Building It
Getting there wasn’t clean.
I used AI to help accelerate parts of the setup — especially around configuration and scripting.
It helped, but not blindly.
Some things worked immediately.
Some were wrong.
Most required iteration.
It reinforced something important:
AI can accelerate execution — but it doesn’t replace understanding.
You still have to know what you’re looking at.
What the System Revealed
Once everything was in place, I started testing real scenarios.
Idle.
Active backup workloads.
And ultimately, system behavior under power loss.
The differences were immediate.
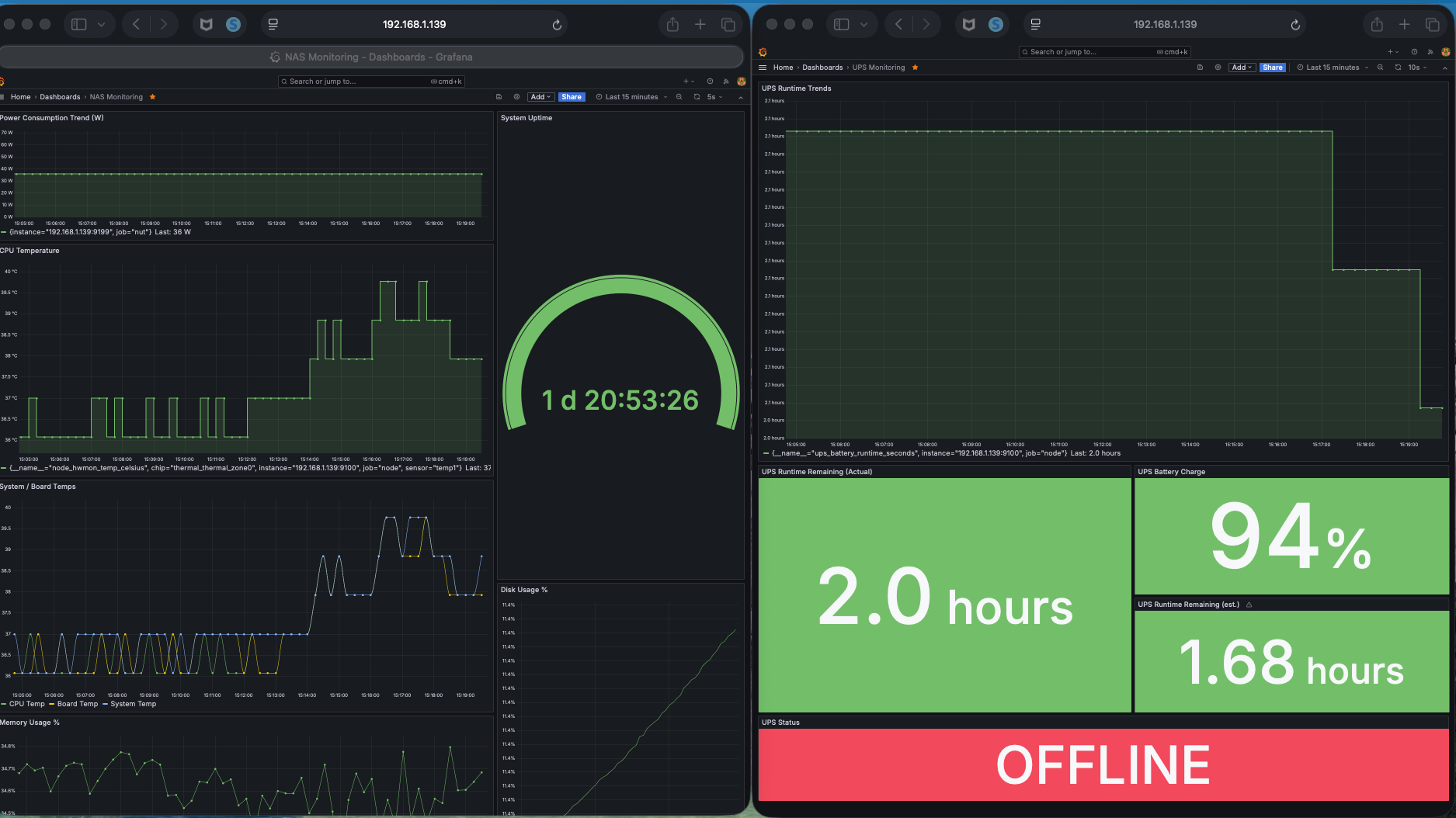
At idle, the system establishes a stable baseline — predictable power, consistent thermal behavior, minimal activity.
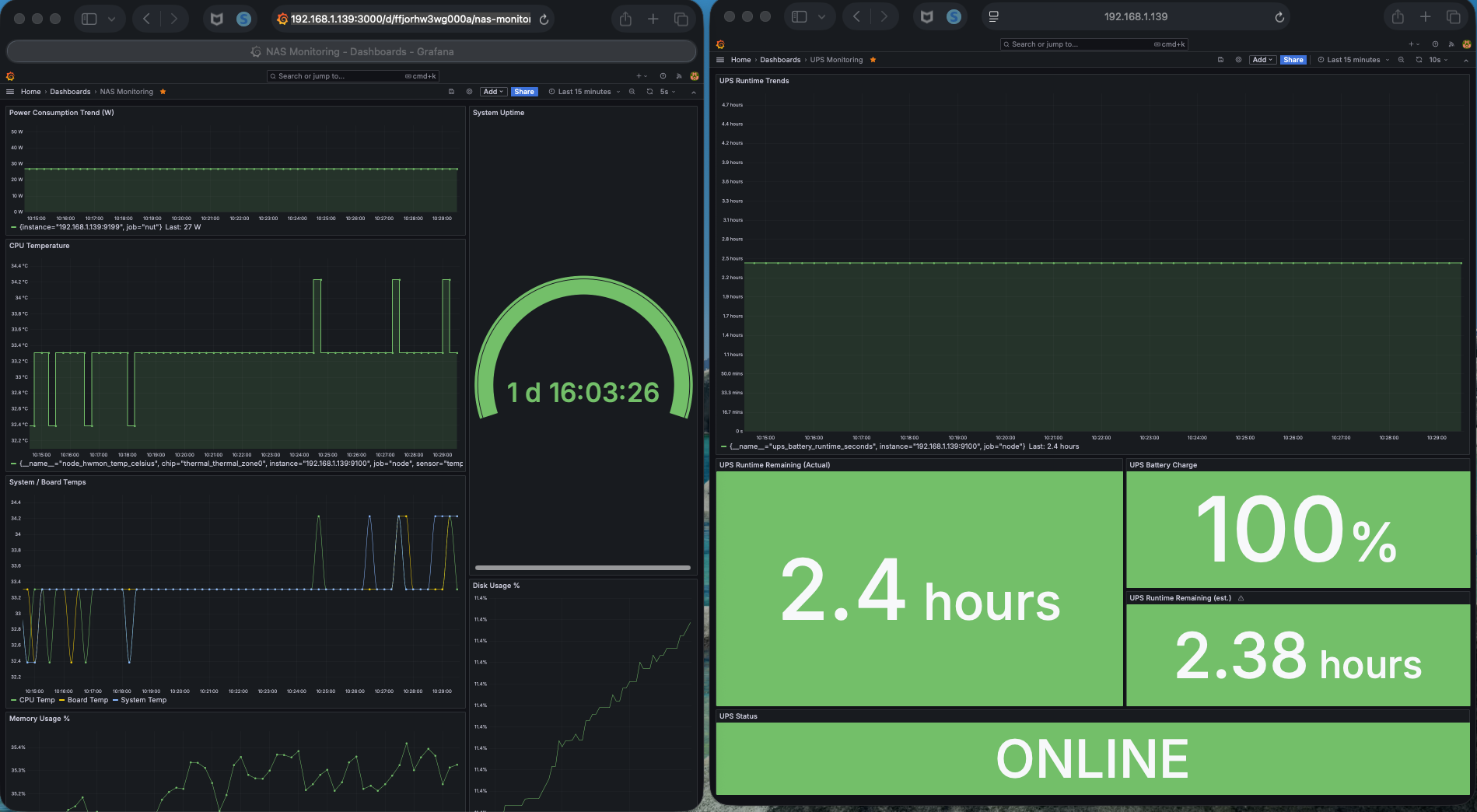
Under load, patterns begin to shift.
Power increases.
Thermal response follows.
System activity becomes more dynamic.
But under load combined with a power event, the behavior becomes far more interesting.
System Behavior Across Conditions
To better understand how the system behaves, I captured four real-world scenarios:
Idle baseline
Backup workload
Backup workload during power loss
Sustained operation under battery
Idle (Plugged In)
Baseline system behavior under normal conditions — stable power, predictable thermal response, and minimal workload activity.
Backup Running (Plugged In)
Under load, power consumption increases and thermal activity follows, reflecting the system’s response to active workload
Backup Running + Power Off (Transition to Battery)
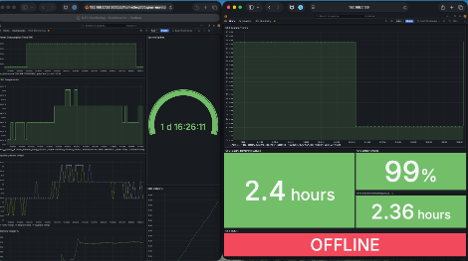
When power is removed under load, the system transitions to battery while the workload continues — and runtime begins to decline.
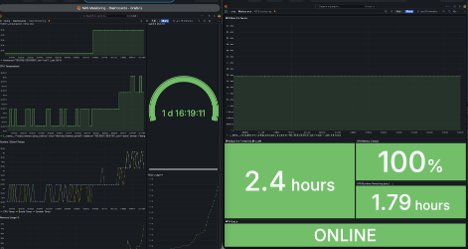
Sustained Operation Under Battery (Load + Power Off)
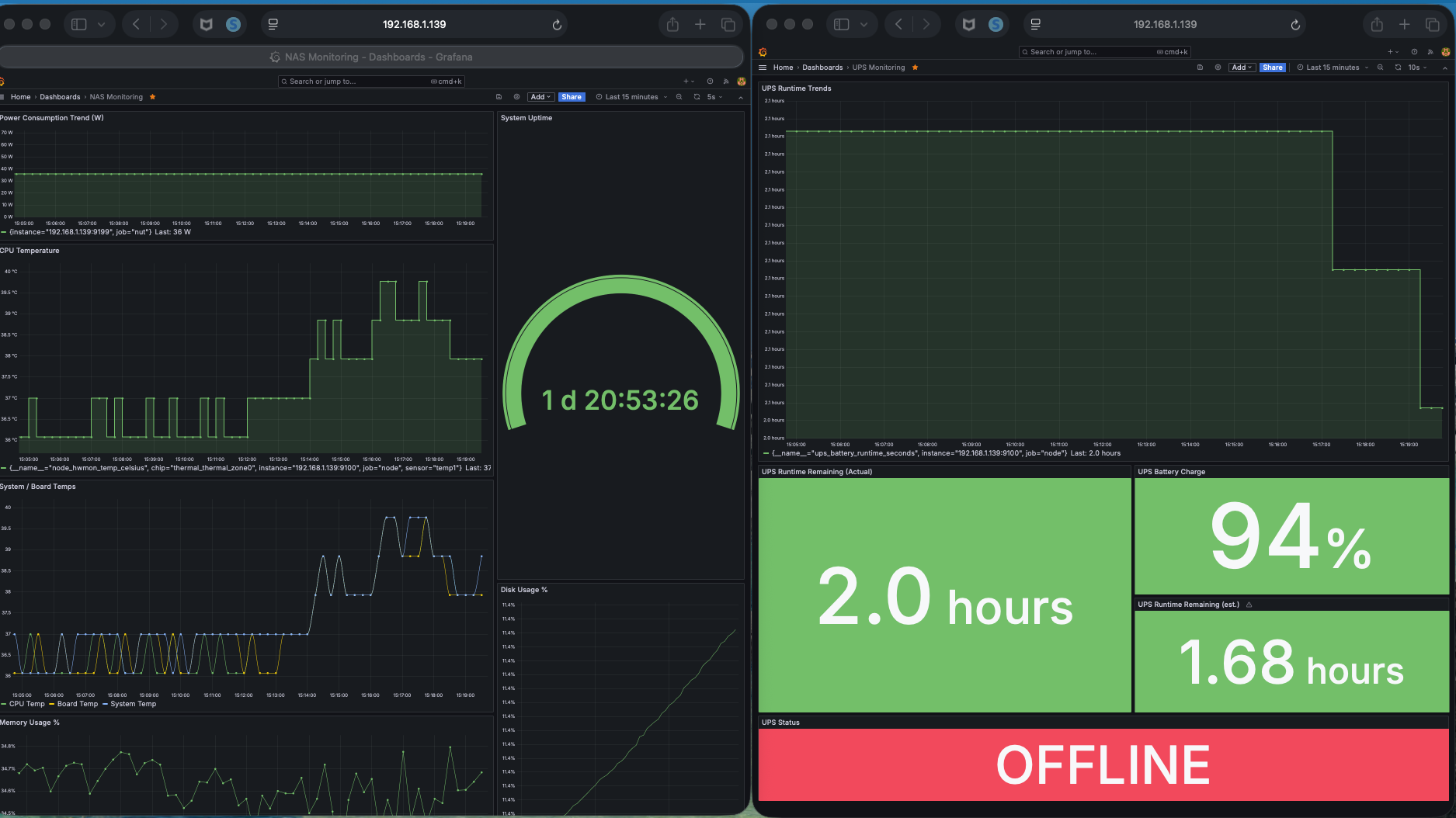
Sustained operation under battery highlights the relationship between workload intensity and runtime degradation, as power, thermal, and system behavior interact in real time.
What stood out wasn’t any single metric — it was how they moved together.
Under normal conditions, the system behaves predictably.
Under load, power and thermal responses begin to shift.
But under load combined with a power event, those relationships become far more dynamic.
This is where a system-level view becomes essential — not just to observe what is happening, but to understand how changes propagate across the system.
Final Thought
This started as a way to monitor my system.
It became something more useful:
a way to understand it.
Preventative maintenance isn’t about reacting to failure.
It’s about recognizing change early enough to act before it matters

The Gravity of AI: Why Intelligence Is Moving From the Cloud to the Edge
Why power, latency, and deployment economics are reshaping where AI runs.
As AI expands into vehicles, healthcare, industrial systems, and infrastructure, intelligence increasingly needs to operate closer to where data is created. This piece explores why power, latency, and deployment economics are pushing AI from centralized cloud models toward edge and hybrid architectures.
Read the full article and discussion on LinkedIn →


AI at Scale Is Forcing a Rethink of Power and Performance
Practical perspectives on AI, edge intelligence, and real-world deployment challenges.
Imagine driving on a dark road when a moose steps into your lane.
There’s no time to send data to the cloud.
The vehicle must detect, decide, and react instantly.
Now imagine a wearable detecting a dangerous heart rhythm — or a fall in the home of an elderly patient.
These decisions can’t wait either.
As AI moves into the physical world — vehicles, healthcare, factories, and infrastructure — intelligence increasingly needs to operate in real time, close to where events occur.
This is shifting focus from raw performance toward efficiency, latency, and reliability.
At the edge, ultra-low-power intelligence enables immediate response where connectivity and energy are limited.
At hyperscale, power consumption is becoming a dominant driver of total cost of ownership and operation. Data centers are gravitating toward regions with lower land and energy costs, while more efficient processing approaches are being explored to manage energy density and operating expense.
AI isn’t just scaling in capability.
It’s forcing a rethink of where and how intelligence runs.
Less about more compute.
More about smarter placement of intelligence.
Read the full article and discussion on LinkedIn ->

Additional Perspectives
Managing Risk in Product & Project Development
Successful product development is not just about innovation — it’s about identifying risk early, aligning stakeholders, and maintaining execution discipline. In complex environments, unmanaged risk often becomes the primary driver of cost overruns, delays, and program failure.
Being Deliberate About AI Adoption
AI delivers the greatest value when applied with clear purpose and measurable outcomes. Organizations benefit most when AI initiatives are aligned with operational realities and business objectives — rather than deployed simply because the technology is available.